
FATS–Faculty of Advanced Techno-Surgery
The Faculty of Advanced Techno-Surgery is a group of researchers that supports a series of innovative modalities with technology to provide seamless support before, during, […]

The Faculty of Advanced Techno-Surgery is a group of researchers that supports a series of innovative modalities with technology to provide seamless support before, during, […]

by Sarah Amini (an MSc student in the AP Lab @ Concordia University and Trainee in the Surgical Innovation Program) The Surgical Innovation graduate training […]

I am very pleased to host the 33rdInternational Conference on Computer Assisted Radiology and Surgery in my hometown of Rennes (France) June 17-21, 2019. Rennes […]

I’m Dr. Pedro Alvarez Diaz MD, Ph.D., a specialist in Orthopedic Surgery and Traumatology, Professor of Orthopedic Surgery and Traumatology and Director of the Anatomy […]

by Hugo Herrero Antón de Vez, MD Recently, I have begun studying machine learning (ML) algorithms for medical applications. I have applied some of them at a […]
by Pascal Fallavollita The industrialized world is in the midst of an “AI awakening”, however AI translation in healthcare systems must learn from decades of experience […]

by Reuben R Shamir A few years ago, we have traveled with the kids to Fort Snelling, Minnesota on the 4th of July. Fort Snelling […]
Cutting Edge is the newsletter of the International Society of Computer Aided Surgery (ISCAS). It provides a platform for informal communication among the members of […]

by Pierre Jannin Dear colleagues, I am pleased to welcome you for the next CARS conference in Rennes (France) from June 18-21, 2019. For its […]
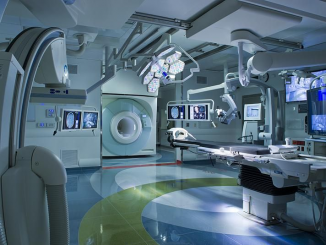
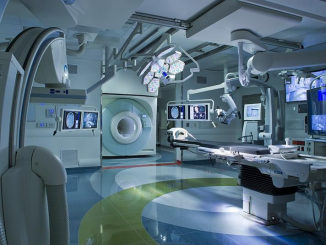
The AMIGO suite. Image courtesy of The Ferenc Jolesz National Center for Image Guided Therapy. by Simon Drouin, Postdoctoral Fellow in the Surgical Planning Laboratory […]
Copyright © 2024 | WordPress Theme by MH Themes